mvn clean fabric8:deploy
Deploying Apache Spark clusters with Fabric8
Introduction
This demo shows how to use the Fabric8 Maven Plugin to deploy a Spark cluster on Openshift.
The application simulates a movie delivery website (like Youtube, or Netflix) where users can rate movies and get recommendations from the system. Recommendations are computed by a backend Apache Spark cluster running a basic collaborative filtering algorithm called "slope one".
Architecture
A high level overview of the final system is summarized in the following schema:
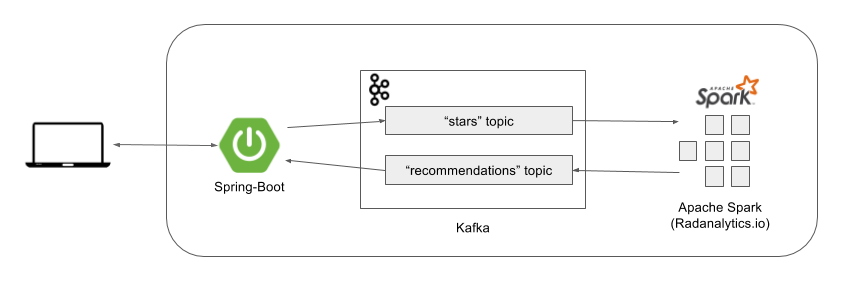
The system is composed of:
-
A Spring-Boot front-end application: delivering static content and exposing rest services through which the UI can send ratings and lookup recommendations. Apache Camel is used for all integration purposes.
-
A Kafka broker with two topics: "stars" containing all ratings from the users; "recommendations" containing recommendations sent by the Spark application.
-
An Oshinko Spark cluster: it computes the recommendations and pushes them back to Kafka.
This is a demo application, so components are not intended for production usage. E.g. the Kafka broker (containing also Zookeeper) cannot be scaled out. The Spark application computes recommendations in a window of 10 minutes for simplicity. The web application is using a local cache to store recommendations received from Kafka, so only one instance should be running.
Installation
The demo requires an Openshift installation. All three components are hosted in different git repositories and can be installed on Openshift using the Fabric8 Maven Plugin.
The first step is to deploy the Kafka broker. You can clone the repository at the following link, then execute the following command from the project root:
The Fabric8 Maven Plugin will use the current Openshift session to access Openshift. You’re automatically logged in when you create a new cluster,
or you can use the command oc login to authenticate again.
The second step is to deploy the web application. You can clone the repository at the following link and run
a mvn clean fabric8:deploy -Dfabric8.mode=openshift (the Fabric8 mode should be set explicitly to openshift for this application).
Finally, you need to deploy the Spark cluster. Make sure you are connected to an OpenShift cluster and are in a project with Oshinko installed. See Get Started if you need help.
Once the Oshinko resources are installed, you can deploy the Spark application.
You can clone the repository at the following link and run
a mvn clean fabric8:deploy command.
Usage
The Fabric8 Maven Plugin automatically creates a route on Openshift, so you should be able to access the web application by clicking on the link provided in the UI.

You’re logged as "user 1" when you access the application. You can give a high rating to the first three movies in the list and the ratings will be sent to Kafka. You can then switch to "user 2" (in the upper part of the UI, there are 4 simulated users) and give a high rating to just the first movie. Wait some seconds and you should get a recommendation for movies 2 and 3, since "user 1" has liked them.
Expansion
The "Slope One" algorithm is a basic collaborative filtering algorithm implemented using the "old" (pre Spark 2.0) APIs. It would be interesting to replace the algorithm with an advanced one, e.g. using Spark machine learning library.
There is a project here showing how one can implement a CI-CD pipeline on Openshift to continuously deliver all three artifacts in a DevOps fashion. It can be used or changed to develop more complex pipelines.